The Problem (and an honest reframing)
Why a cascade — and what we learned when the data did not match the architecture
The factory floor
A rolling mill produces a continuous strip of steel at speed. A line-scan camera captures a frame every few milliseconds. The vast majority of those frames show a perfectly acceptable surface. A small minority contain a scratch, an inclusion, a patch of rolled-in scale, a pit. A defect that slips through is expensive; a false alarm that stops the line is also expensive.
The naive solution is to pipe every frame through the most capable model you have access to — today, that means a multimodal LLM such as GPT-4o. At ~3 seconds and ~$0.002 per call, that does not survive contact with a 100 fps camera.
The realistic solution is a cascade: a cheap, fast model rejects the easy negatives; a specialist handles the routine positives; an expensive oracle is reserved for the genuinely ambiguous frames where being right matters more than being fast.
What the camera actually sees
The v1 demonstration is built on the NEU Metal Surface Defects dataset (mirrored on HuggingFace as newguyme/neu_cls). Below is one real example of each of its six defect classes — the entire vocabulary the system has to recognise.

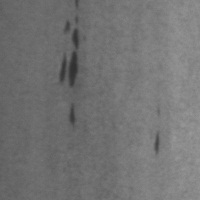
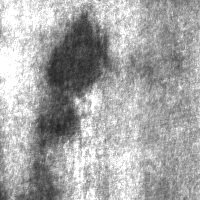

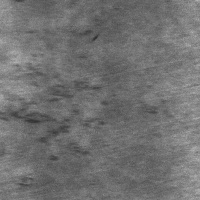

And here is what should sit alongside them — a row of defect-free surface samples representing what the camera sees the other 90%+ of the time:
Why this shape of architecture wants a particular shape of data
The cascade only pays off when the cheap layers can confidently dispose of most of the workload. That presupposes:
- A large pool of “normal” examples, against which an unsupervised model (here, a convolutional autoencoder) can learn what unremarkable looks like.
- A small, varied pool of defects — enough to train a specialist detector and to give a few-shot oracle some grounding, but not so many that you no longer need the cheap layers.
The shape of the data the real world presents is roughly 8:1 to 100:1 normal-to-defect. That is exactly where a gatekeeper-autoencoder earns its place: most frames reconstruct cleanly, MSE is low, and they exit the pipeline in single-digit milliseconds.
What we actually built v1 on — and why we had to be honest about it
NEU contains 1,800 images, perfectly balanced across six defect classes, and zero “normal” images. That is a benchmark designed for defect classification, not defect detection. It is the wrong shape of data for the architecture we built:
- The autoencoder has no genuine “normal” class to learn. Trained on everything, it learns to reconstruct defects, and its MSE distribution becomes uninformative.
- We worked around it by treating one class (
rolled-in_scale, the most internally consistent texture) as a proxy for normal and training the AE only on those 237 frames. The threshold of 0.0067 separates that class from the others (per-class MSE inscripts/ae_sanity.pyconfirms this —patches0.028,pitted_surface0.043,rolled-in_scale0.003). - This works as a demo and the live cascade does drop ~53% of frames at Layer 1, but it is a contrived setup. It tells us the cascade plumbing is sound. It does not tell us that an autoencoder is the right gatekeeper for this data — because for this data, it isn’t.
The honest takeaway from the v1 evaluation:
| Metric | Cascade | Oracle-only baseline |
|---|---|---|
| Cost per 100k frames | $48 | $107 |
| Accuracy on classified frames | 100% (27/27) | 96.7% |
| p50 latency | 195 ms | 2,147 ms |
| L1 drop rate | 53% | n/a |
The cascade saves 55% on cost and is an order of magnitude faster, and every frame it commits an answer to is correct. But it only commits to ~45% of frames; the other ~55% are dropped at L1 because they look “normal-ish” against a rolled-in-scale baseline. On a balanced multi-class benchmark, dropping a frame is wrong by definition — there is no “no defect” answer. So the overall accuracy reads as 0.45 even though the pipeline is, in its own terms, behaving correctly.
What v2 needs
The v2 demonstration (specced as Phase J in the plan) swaps in a dataset whose shape matches the architecture:
VisA — Visual Anomaly Detection (Amazon Science, 2022)
| Property | Value |
|---|---|
| Total images | 10,821 |
| Normal | 9,621 |
| Anomalous | 1,200 |
| Categories | 12 (PCB, capsules, candles, cashews, …) |
| Format | MVTec-AD style: train/good, test/good, test/bad, segmentation masks |
| License | CC BY 4.0 (commercial use OK) |
| Access | Direct S3 download — no signup wall |
VisA delivers:
- A genuine 8:1 normal-to-anomaly ratio — exactly the regime where a gatekeeper AE is the right tool.
- Pixel-level segmentation masks — which convert cleanly to bounding boxes for YOLO training.
- A small set of bad examples per category — perfect raw material for the few-shot Oracle prompt.
- Twelve categories — we can pick one (likely
pcb1for structural complexity, orcandlefor texture) without committing to a multi-domain training run.
We also considered MVTec AD — the original benchmark in this space — but it ships under CC BY-NC-SA 4.0 (non-commercial only) and requires a signup form, which makes it a poor choice for an open portfolio repository. VisA is newer, larger, more permissive, and downloadable in one command.
What this site walks through
- Architecture — the three layers, the routing logic, the deployed Azure topology.
- Data Strategy — splits, pseudo-labelling, the few-shot prompt design.
- Evaluation — the v1 numbers above, with the dual-accuracy framing made explicit.
The reflection is the point. Building the pipeline was the easy half; recognising that the demonstration dataset did not exercise the architecture’s strengths — and saying so plainly — is the half that actually matters in a portfolio.
- The autoencoder has no genuine “normal” class to learn. Trained on everything, it learns to reconstruct defects, and its MSE distribution becomes uninformative.
- We worked around it by treating one class (
rolled-in_scale, the most internally consistent texture) as a proxy for normal and training the AE only on those 237 frames. The threshold of 0.0067 separates that class from the others (per-class MSE inscripts/ae_sanity.pyconfirms this —patches0.028,pitted_surface0.043,rolled-in_scale0.003). - This works as a demo and the live cascade does drop ~53% of frames at Layer 1, but it is a contrived setup. It tells us the cascade plumbing is sound. It does not tell us that an autoencoder is the right gatekeeper for this data — because for this data, it isn’t.
The honest takeaway from the v1 evaluation:
| Metric | Cascade | Oracle-only baseline |
|---|---|---|
| Cost per 100k frames | $48 | $107 |
| Accuracy on classified frames | 100% (27/27) | 96.7% |
| p50 latency | 195 ms | 2,147 ms |
| L1 drop rate | 53% | n/a |
The cascade saves 55% on cost and is an order of magnitude faster, and every frame it commits an answer to is correct. But it only commits to ~45% of frames; the other ~55% are dropped at L1 because they look “normal-ish” against a rolled-in-scale baseline. On a balanced multi-class benchmark, dropping a frame is wrong by definition — there is no “no defect” answer. So the overall accuracy reads as 0.45 even though the pipeline is, in its own terms, behaving correctly.
What v2 needs
The v2 demonstration (specced as Phase J in the plan) swaps in a dataset whose shape matches the architecture:
VisA — Visual Anomaly Detection (Amazon Science, 2022)
| Property | Value |
|---|---|
| Total images | 10,821 |
| Normal | 9,621 |
| Anomalous | 1,200 |
| Categories | 12 (PCB, capsules, candles, cashews, …) |
| Format | MVTec-AD style: train/good, test/good, test/bad, segmentation masks |
| License | CC BY 4.0 (commercial use OK) |
| Access | Direct S3 download — no signup wall |
VisA delivers:
- A genuine 8:1 normal-to-anomaly ratio — exactly the regime where a gatekeeper AE is the right tool.
- Pixel-level segmentation masks — which convert cleanly to bounding boxes for YOLO training.
- A small set of bad examples per category — perfect raw material for the few-shot Oracle prompt.
- Twelve categories — we can pick one (likely
pcb1for structural complexity, orcandlefor texture) without committing to a multi-domain training run.
We also considered MVTec AD — the original benchmark in this space — but it ships under CC BY-NC-SA 4.0 (non-commercial only) and requires a signup form, which makes it a poor choice for an open portfolio repository. VisA is newer, larger, more permissive, and downloadable in one command.
What this site walks through
- Architecture — the three layers, the routing logic, the deployed Azure topology.
- Data Strategy — splits, pseudo-labelling, the few-shot prompt design.
- Evaluation — the v1 numbers above, with the dual-accuracy framing made explicit.
The reflection is the point. Building the pipeline was the easy half; recognising that the demonstration dataset did not exercise the architecture’s strengths — and saying so plainly — is the half that actually matters in a portfolio.