Inference walkthroughs
What the cascade actually sees, layer by layer
This page walks through three frames from the production cascade — one for each behaviour the architecture is designed to produce. Every panel is generated from the actual end-to-end trace at reports/eval_cascade_metal_k1_calibrated.jsonl by scripts/render_inference_panels_metal.py.
For each example you get three panels:
- Input — the raw frame as the camera saw it, resized for display.
- PatchCore heatmap — per-patch cosine distance to the nearest neighbours in the domain memory bank, overlaid in inferno colourmap. Bright regions are “looks unlike anything in the normal-distribution training pool”.
- YOLO overlay — top-3 detections from the production
models/yolo_metal/best.pt(mAP50 0.50, trained 50 ep / 640 px on a T4 in Phase J.4). Red is the highest-confidence box, amber are runners-up.
The trace beneath each example is the literal router output — same code paths the live ACA app exercises, just re-run in-process for cheaper iteration.
L1 fast path — clean steel, gated in <500 ms
Track A, domain severstal, true polarity normal, router stopped at L1 (end-to-end 527 ms).
Severstal in-domain. PatchCore reconstructs the surface below the calibrated z-threshold, the cascade returns no_defect immediately, no L2 / L3 cost. Roughly 95 % of a real factory feed looks like this.

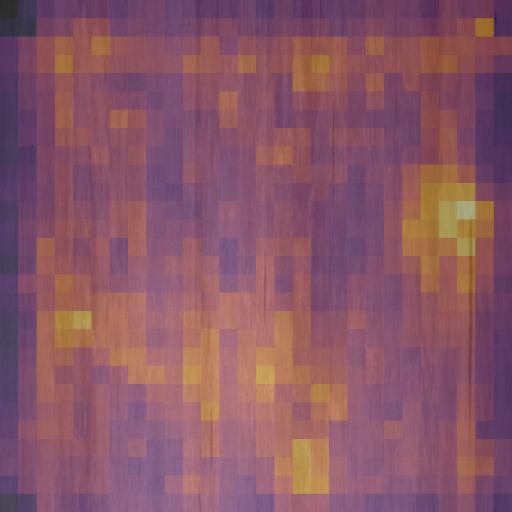

Router trace
| Layer | Decision | Class | Score | Latency |
|---|---|---|---|---|
| L1 | no_defect | - | z=-1.03 (τ=-0.5) | 527 ms |
L2 production YOLO — defect classified, no Oracle bill
Track A, domain severstal, true polarity defective, router stopped at L2 (end-to-end 430 ms).
Severstal defective frame. PatchCore escalates at L1, the production YOLO (mAP50 0.50, trained 50 ep / 640 px on T4) returns a confident detection ≥ 0.5, the cascade short-circuits at L2 — no AOAI tokens spent. This is what the J.4 GPU retrain buys versus the smoke YOLO.



Router trace
| Layer | Decision | Class | Score | Latency |
|---|---|---|---|---|
| L1 | defect | - | z=-0.04 (τ=-0.5) | 403 ms |
| L2 | defect | scratch | conf=0.65, n=3 | 26 ms |
L3 Oracle backstop — KSDD2 OOD defect, AE escalates
Track B, domain ksdd2, true polarity defective, router stopped at L3 (end-to-end 3415 ms).
KSDD2 (commutator surfaces) is a different metal domain — the Severstal-trained YOLO has no class for it, so the router skips L2 by design. PatchCore flags the anomaly, the Oracle classifies it as surface_anomaly with a one-line rationale. This is the architectural payoff: pay the AOAI token cost only on frames where the cheap layers can’t decide.

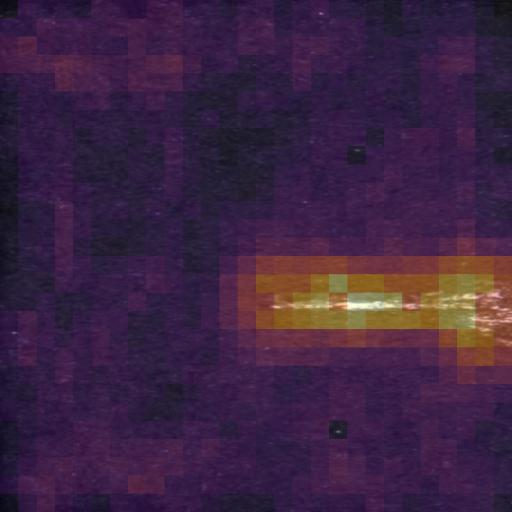

Router trace
| Layer | Decision | Class | Score | Latency |
|---|---|---|---|---|
| L1 | defect | - | z=16.33 (τ=1.0) | 254 ms |
| L3 | scratch | scratch | conf=0.85 | 3161 ms |
Oracle reasoning: The image shows a long, thin, bright linear mark consistent with a scratch defect on the metal surface.
Reading guide
When inspecting the panels:
- PatchCore heatmaps on Track A defectives should spotlight the region YOLO subsequently boxes. If the bright region sits anywhere YOLO ignores, the per-domain
τis too tight. - Heatmaps on Track A normals should be mostly cold. Hot patches on clean steel are a sign the calibration was done against the wrong distribution.
- Oracle reasoning strings should reference the visible defect type rather than generic “surface irregularity” boilerplate. The few-shot prompt in
oracle.pywas rewritten in J.2 around the Severstal+KSDD2 taxonomy specifically to ground the model. - YOLO box colours — red is the top detection, amber are runners-up. Track B (KSDD2) frames are deliberately out-of-distribution for the Severstal-trained YOLO; expect noisy class labels that the Oracle then corrects.