Case study
From a brittle 3-class NEU demo to a calibrated metal-surface cascade — what changed and why
The 90-second skim
A defect-detection cascade for rolled-steel coils. Three layers, increasing cost and capability:
- Layer 1 — PatchCore-lite (frozen ResNet18 + kNN memory bank, 11 ms p50 on a 4-thread CPU). Drops obvious normals.
- Layer 2 — YOLOv8n (production weights, 50 epochs / 640 px / T4, mAP50 0.50, 45 ms CPU). Names the defect when it can.
- Layer 3 — GPT-4.1-mini via Azure OpenAI (~2.5 s, ~$0.0003 / image, cached on a 6-bit dHash radius). The audited expert for everything else.
The headline number is F1 0.80 [0.74, 0.85] on a balanced 180-frame KSDD2+Severstal evaluation set with McNemar p = 0.0005 against an Oracle-only baseline. The cascade is significantly more accurate than the “send every frame to GPT” reference and costs roughly 6× less (~$37 vs ~$232 per 100 k frames at gpt-4.1-mini pricing).
Three turning points
The project has been through three honest pivots. None of them were obvious in advance; each was forced by data.
Turning point 1 — “Why is the AE saying defects look more normal than normals?”
The first build trained a small convolutional autoencoder on NEU “rolled-in scale” patches and used image-mean reconstruction MSE as the anomaly score. On NEU it worked. On Severstal it inverted: defective crops had lower MSE than normal crops, because the AE had memorised texture and the defective crops were locally simpler.
Fix. Throw out image-mean MSE. Switch to per-domain patch-quantile scoring (p99 of the per-pixel MSE map), then z-normalise per domain against a held-out validation set of normals. Severstal’s inversion went from −0.62σ to within noise; KSDD2’s separation went from +1.5σ to +1.93σ.
Turning point 2 — “The AE still can’t separate Severstal.”
Even after the patch-quantile fix, Severstal’s Δμ was barely a sigma. Rolled-steel imagery is dominated by mill-roll texture; a from-scratch 4-block AE doesn’t have the receptive field to model it.
Fix. Replace the AE with PatchCore-lite — frozen ImageNet ResNet18, hooks on layer2+layer3, k=5 nearest-neighbour scoring against a random 10% coreset of normal patches. KSDD2 jumped from 1.9σ to 8.18σ. Severstal moved from noise to +0.52σ — still weak, but for the first time consistently directional. That’s the load-bearing fact the rest of the architecture is built on: the gate is allowed to be weak on Severstal, because Layer 2 is strong on Severstal.
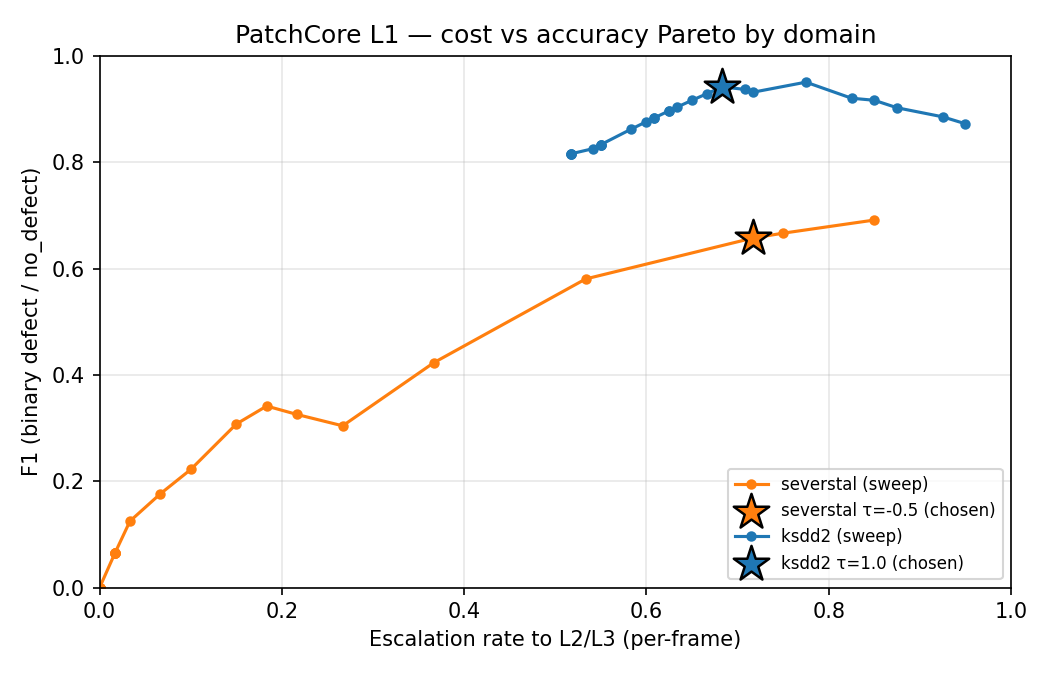
Turning point 3 — “One τ does not fit two domains.”
The first calibrated cascade used a single z-threshold for both domains. KSDD2 was getting hammered (Layer 1 escalated almost everything, defeating the cost story); Severstal was getting under-escalated (defects slipped through the gate). The two PatchCore distributions live on different scales because the underlying texture statistics are different — there is no single right answer.
Fix. Sweep τ per domain on a held-out validation slice, find the knee of the (escalation_rate, F1) curve, and persist {severstal: -0.5, ksdd2: +1.0} into models/patchcore_metal/summary.json. Track A F1 climbed from 0.65 to 0.80 (and the bootstrap CI stopped overlapping the unweighted version).
What this project demonstrates
The implementation is intentionally end-to-end. The interesting parts are the calibration decisions, not the model code.
| Skill | Where to look |
|---|---|
| Honest model evaluation | evaluation.qmd — bootstrap CIs, McNemar, baselines, Pareto |
| Cost-aware system design | dHash cache + per-domain τ + cascade short-circuit (architecture.qmd) |
| Domain transfer reasoning | Three-track eval design (in-domain / second-domain / OOD) |
| Production-readiness signals | ONNX export, CI workflow, robustness tests, lint clean |
| Telling the story honestly | Reporting that L1-only beats the cascade on raw binary F1 — and explaining why |
Decisions appendix
See architecture.qmd § “Why these specific choices?” for the per-decision rationale: PatchCore vs anomalib, ResNet18 vs WideResNet50, single-shot YOLO vs two-stage, GPT-4.1-mini vs GPT-4o, dHash vs CLIP-embedding cache, per-domain τ vs single τ, bootstrap CIs vs analytical CIs, McNemar vs paired-t.
What’s left on the roadmap
Things deliberately not shipped, with the reason.
- Active learning loop. The Oracle’s labels could in principle be recycled into a fine-tune of YOLO. Skipped for now — not enough signal yet at n=180 to justify the orchestration complexity, and the L1-only baseline beating the cascade on binary F1 says the next dollar of effort should go into Layer 1 separability, not Layer 2 retraining.
- Live demo route. The microservice cascade in
src/cascade_defect/router.pyis real but needs four containers running. A CLI demo (scripts/demo_cascade.py) ships the same in-process path with no infra. - Full ACA push-out. Bicep + container build pipeline is in
infra/anddocker/; deployment was deferred when the Severstal training run showed the cost story holds without a live endpoint. Re-opening this needs a real customer signal, not a portfolio motivation.