4 Scraping a Table
In this section, you will learn how to scrape data from a table on the SARS website, specifically the exchange rates table, and save this data to a pandas DataFrame. Once the data is in a DataFrame, we will also demonstrate how to save it as a JSON file for further use.
4.0.0.1 1. Inspecting the Webpage
The first step in web scraping is to inspect the webpage to identify the structure and the elements you want to extract. The SARS Rates of Exchange page contains a table with exchange rates for various currencies. This table is defined using standard HTML <table> tags, with each row (<tr>) containing data for a different currency.
Here is a screenshot of the exchange rates table on the SARS website:
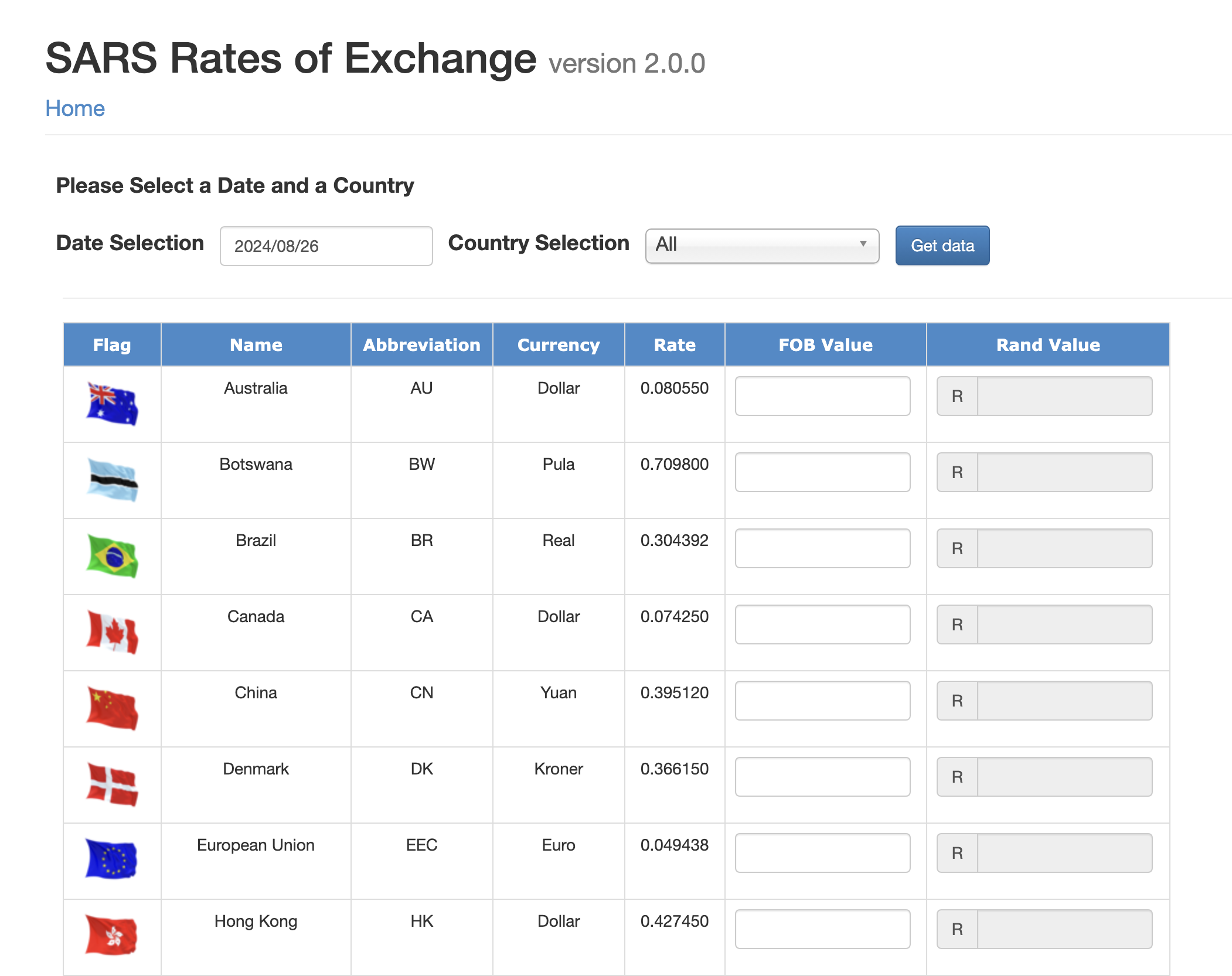
To scrape this table, we’ll focus on extracting the following data for each currency: - Country name - Abbreviation - Currency name - Exchange rate
The HTML structure of the table includes: - A table element with class table table-bordered gvExt. - Each row (<tr>) contains several cells (<td>), where: - The first cell contains the country flag (which we will ignore). - The second cell contains the country name. - The third cell contains the currency abbreviation. - The fourth cell contains the currency name. - The fifth cell contains the exchange rate.
4.0.0.2 2. Setting Up Your Environment
Before we start scraping, ensure that you have the necessary Python libraries installed in your virtual environment. We will use requests to fetch the webpage content, BeautifulSoup to parse the HTML, and pandas to store the data in a DataFrame.
pip install requests beautifulsoup4 pandas4.0.0.3 3. Writing the Scraper
Below is the step-by-step guide to scraping the exchange rates table from the SARS website:
4.0.0.3.1 3.1 Importing the Required Libraries
Start by importing the necessary libraries.
import requests
from bs4 import BeautifulSoup
import pandas as pd4.0.0.3.2 3.2 Sending a GET Request to Fetch the Webpage
We’ll send an HTTP GET request to retrieve the HTML content of the webpage.
url = "https://tools.sars.gov.za/rex/Rates/Default.aspx"
response = requests.get(url)
if response.status_code == 200:
print("Successfully fetched the webpage!")
else:
print(f"Failed to fetch the webpage. Status code: {response.status_code}")4.0.0.3.3 3.3 Parsing the HTML with BeautifulSoup
Next, parse the HTML content using BeautifulSoup.
soup = BeautifulSoup(response.text, 'html.parser')4.0.0.3.4 3.4 Locating the Table and Extracting Data
We will locate the table by its class name and then iterate over the rows to extract the relevant data.
# Locate the table
table = soup.find('table', {'class': 'table table-bordered gvExt'})
# Prepare lists to store the extracted data
countries = []
abbreviations = []
currencies = []
rates = []
# Loop through each row in the table
for row in table.find_all('tr')[1:]: # Skip the header row
cells = row.find_all('td')
country = cells[1].text.strip()
abbreviation = cells[2].text.strip()
currency = cells[3].text.strip()
rate = float(cells[4].text.strip())
# Append the data to the lists
countries.append(country)
abbreviations.append(abbreviation)
currencies.append(currency)
rates.append(rate)4.0.0.3.5 3.5 Creating a Pandas DataFrame
Now that we have the data, we can create a pandas DataFrame to organize it.
# Create a DataFrame
df = pd.DataFrame({
'Country': countries,
'Abbreviation': abbreviations,
'Currency': currencies,
'Rate': rates
})
# Display the DataFrame
print(df)4.0.0.3.6 3.6 Saving the Data to a JSON File
Finally, let’s save the DataFrame to a JSON file for further use.
# Save the DataFrame to a JSON file
df.to_json('exchange_rates.json', orient='records', indent=4)
print("Data has been saved to exchange_rates.json")4.0.1 4. Summary
In this section, you learned how to: 1. Inspect a webpage to locate a table for scraping. 2. Write a Python script to scrape data from the table using requests and BeautifulSoup. 3. Store the scraped data in a pandas DataFrame. 4. Save the DataFrame to a JSON file.
This basic approach to scraping tables can be applied to many other websites, allowing you to automate the extraction of tabular data for analysis, reporting, or other applications.
Websites can change their HTML structure over time, which may break your scraper. To maintain your scraping scripts, periodically check the structure of the pages you scrape and update your code as needed.
Task: To practice scraping the SARS exchange rates table, run the provided code in your Python environment and examine the extracted data in the DataFrame. You can also open the exchange_rates.json file to view the saved data.
Try to scrape a table on Wikipedia or another website of your choice if you want to extend yourself further.
In the next section, we will explore how to automate this scraping process using GitHub Actions, enabling you to keep your data up-to-date without manual intervention.