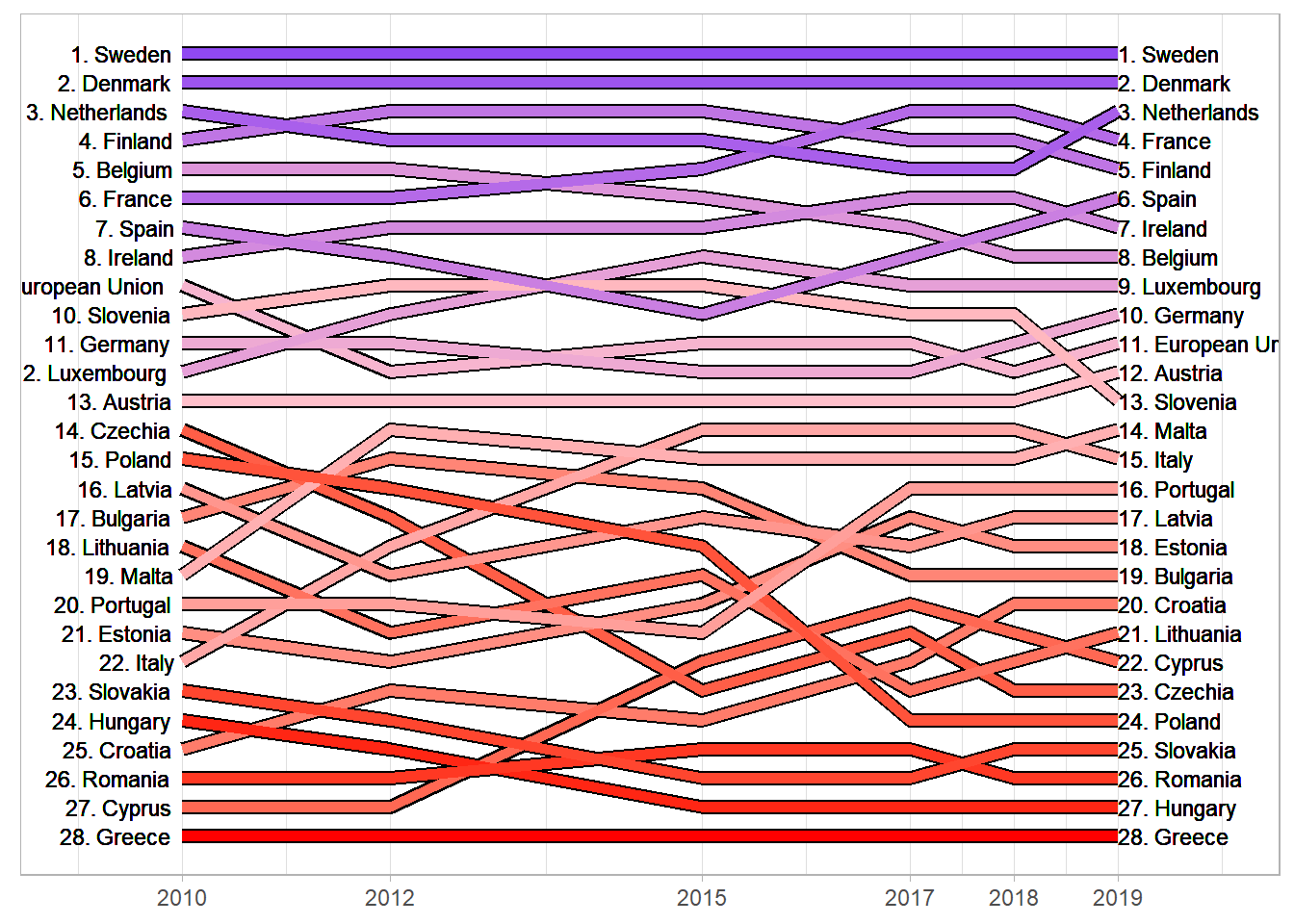
Using ggiraph to recreate an interactive visualization from The Economist.
Author
Jonathan
Published
August 20, 2022
Exploring Gender Equality in the EU
Purpose
Show a workflow in creating an interactive figure and highlight some data munging tips.
Focus is on:
Getting data from excel into R with some nice functions etc.
Interactive charts
Data viz
Intro
Data from landing page and you can download the excel sheet here.
There are more than 140 indicators that fall into 6 domains and 14 sub-domains.
Description of data ingestion
The data comes in a common format – there is an excel workbook with a readme sheet, then a metadata sheet describing the different variables, then a sheet for the years 2010, 2012, 2015, 2017, 2018 and 2019.
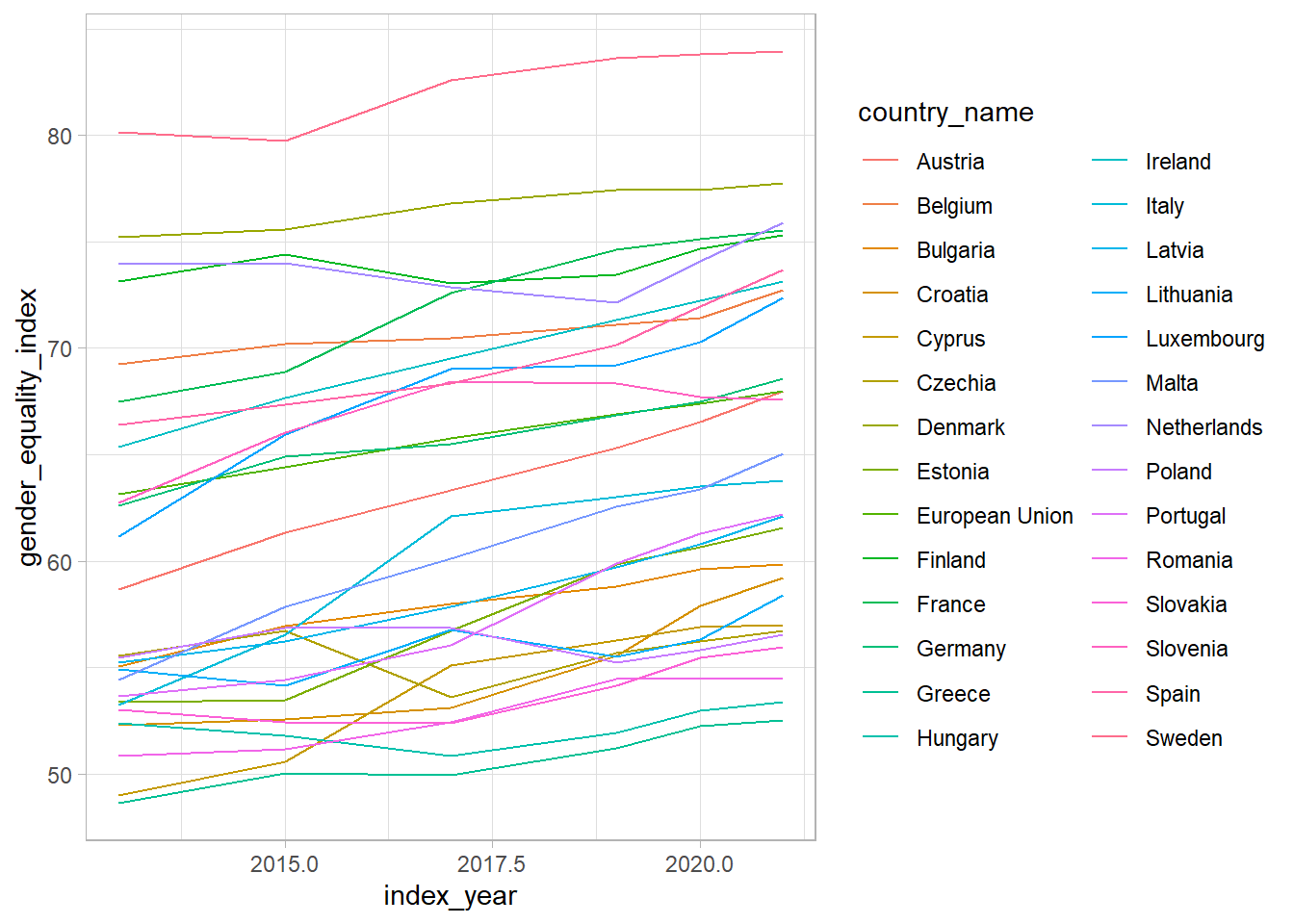
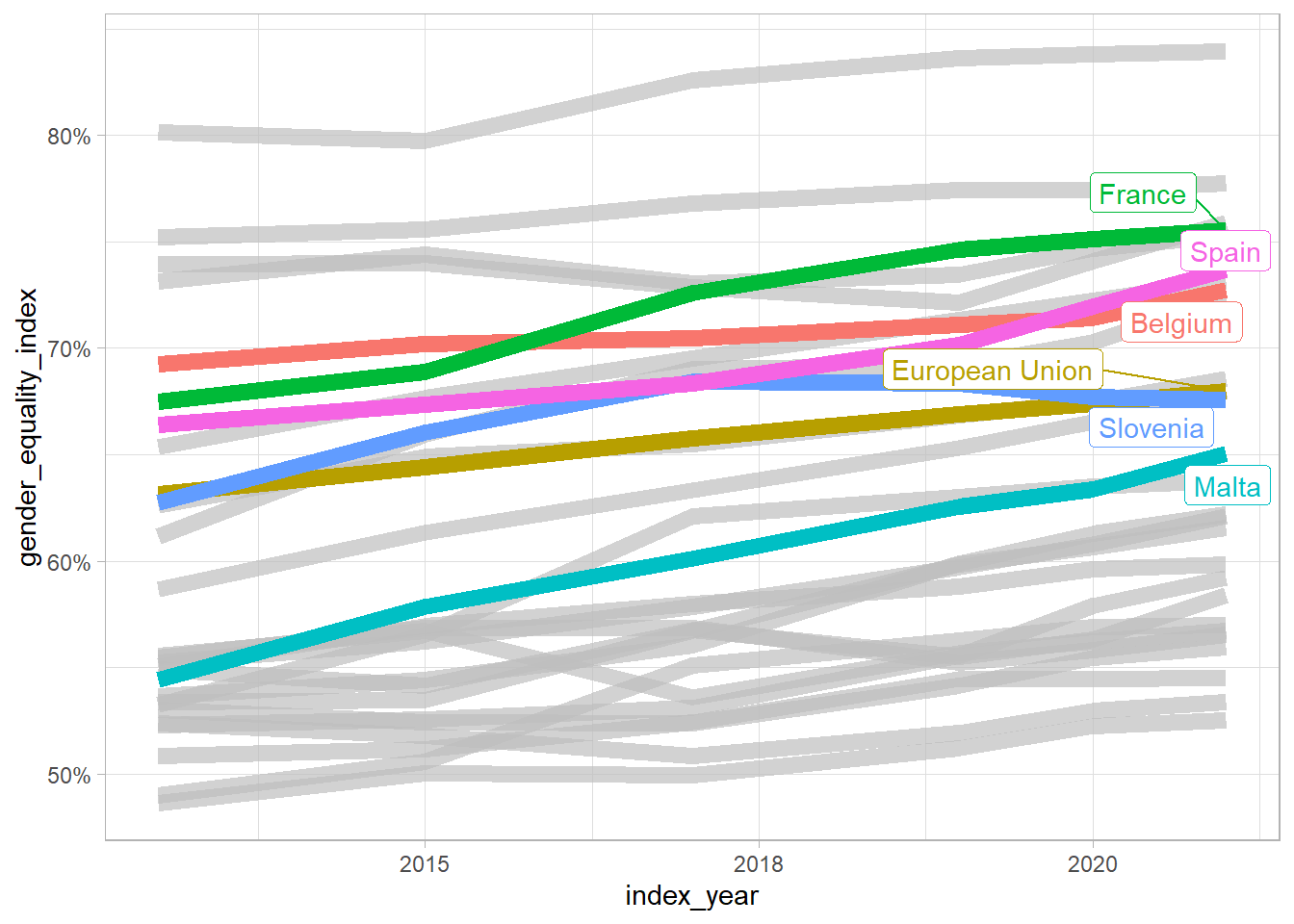
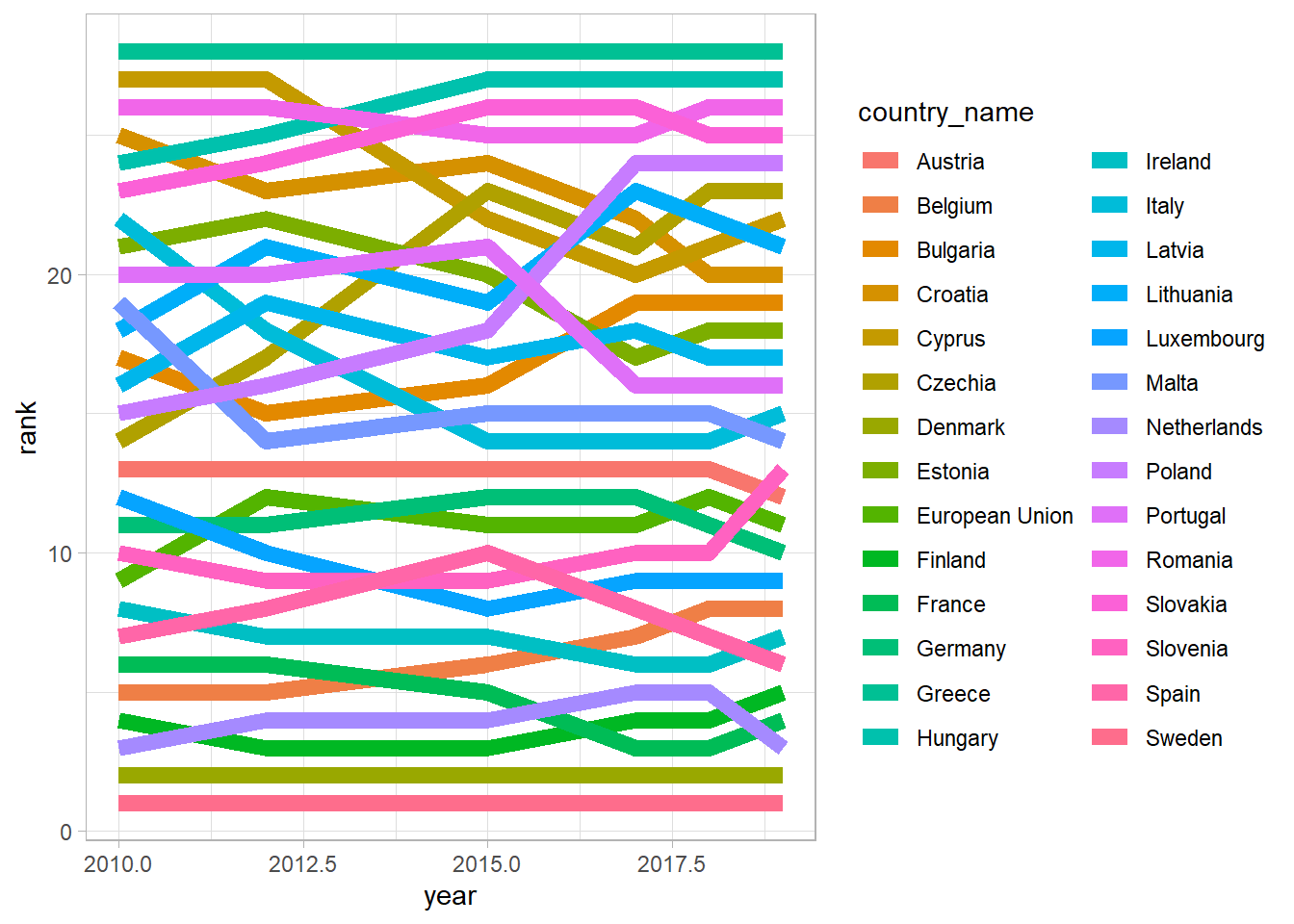
We can make a simple plot of the index changes over time, in relative terms and in absolute terms.
This excel file is meant to provide users the data needed to calculate the Gender Equality Index
Users must use the data provided in these sheets (one per year), to derive the scores of the Gender Equality Index, by applying the methodology for calculation
Gender Equality Index 2017: Methodological Report | European Institute for Gender Equality (europa.eu)
- Users might find in Index Interface different data for some indicators
- In the Index Interface, EIGE is presenting some of them in a different way
- For instance, the indicator on povery (indicator 8), is considered for calculation as NOT-AT-RISK of POVERTY rate, while in the Index interface, the figures are referred to AT-RISK of POVERTY rate
- The same for the indicators on access to health care, displayed as UNMET NEEDS in the Index interface, and used in a reversed way for calculation.
- As for the indicator of the domain of power, the methodology envisages to use the 3-years average, and the figures in the excel are provided accordingly. In the Index interface, the most updated data (quarterly, biannual, year) are displayed instead.
- The Index Inteface provides the information in the notes and metadata for each indicator
Codebook
The problem is that this is written in a silly way - it’s readable to humans but not to computers
# df <- readxl::read_excel(here("data/Gender-equality-index.xlsx"), sheet = 2, range = )
Data read in process
What we want to do is take the wide dataset from the year tabs and then make them long so that we can collect them together and draw some functions over time.
I should make a graphic of how we go from colours having meaning to columns containing this kind of information. Like a panel on the left where we have a screenshot of the excel sheet - then an arrow - then on the right we have a nice simple grouped dataset on the right.
sheets<-tibble( sheet =3:8, year =c(2010, 2012, 2015, 2017, 2018, 2019))get_data<-function(sh){message("Getting data from ", sh)df<-readxl::read_excel(here("data/Gender-equality-index.xlsx"), sheet =sh)df<-df%>%janitor::clean_names()%>%pivot_longer(-c(index_year:gender_equality_index))df}sheets<-sheets%>%mutate(data =map(sheet, possibly(get_data, "failed")))df<-sheets%>%unnest(data)
Data augmentation
Country names
We might want to get the English names of a country
The indicator is calculated as the ratio of real GDP to the average population of a specific year. GDP measures the value of total final output of goods and services produced by an economy within a certain period of time. It includes goods and services that have markets (or which could have markets) and products which are produced by general government and non-profit institutions. It is a measure of economic activity and is also used as a proxy for the development in a country’s material living standards. However, it is a limited measure of economic welfare. For example, neither does GDP include most unpaid household work nor does GDP take account of negative effects of economic activity, like environmental degradation.
gdp_pc<-readxl::read_excel(here("data/Gender-equality-index_augment_with_gdp_pc.xlsx"), sheet =3, range ="A9:AS49")
Warning: Using an external vector in selections was deprecated in tidyselect 1.1.0.
ℹ Please use `all_of()` or `any_of()` instead.
# Was:
data %>% select(cols)
# Now:
data %>% select(all_of(cols))
See <https://tidyselect.r-lib.org/reference/faq-external-vector.html>.
Warning in mask$eval_all_mutate(quo): NAs introduced by coercion
Warning in mask$eval_all_mutate(quo): NAs introduced by coercion
Warning in mask$eval_all_mutate(quo): NAs introduced by coercion
Warning in mask$eval_all_mutate(quo): NAs introduced by coercion
Warning in mask$eval_all_mutate(quo): NAs introduced by coercion
Warning in mask$eval_all_mutate(quo): NAs introduced by coercion
Warning in mask$eval_all_mutate(quo): NAs introduced by coercion
Warning in mask$eval_all_mutate(quo): NAs introduced by coercion
Warning in mask$eval_all_mutate(quo): NAs introduced by coercion